Transfer Learning: Domain Generalization Performance of supervised training on GTA5 and SYNTHIA. * denotes that the ViT-L-16 was used as the encoder. ◦ denotes that ViT-L-14 was used as the encoder. 🔒 denotes frozen encoder weights.
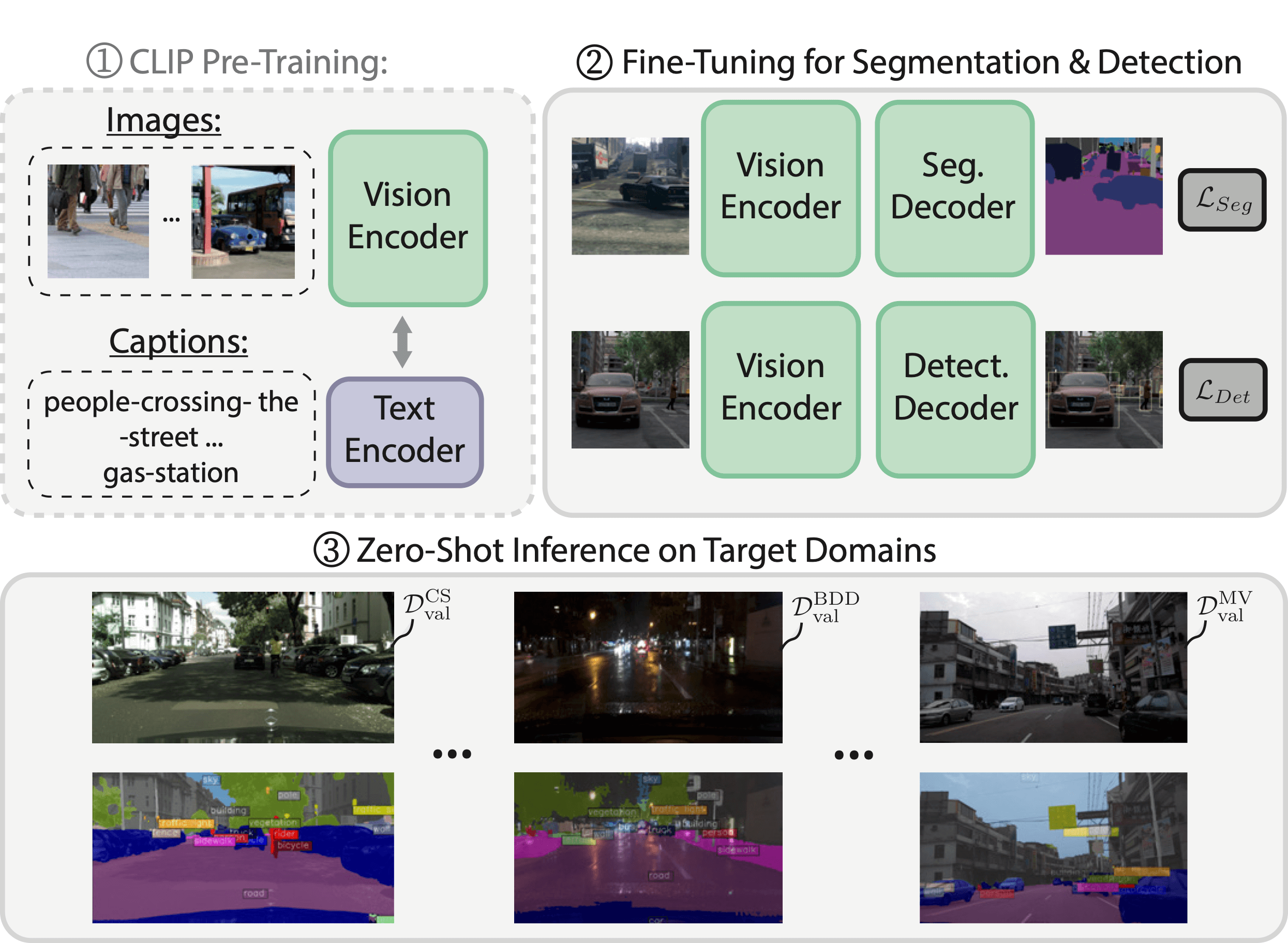
Domain generalization (DG) remains a significant challenge for perception based on deep neural networks (DNNs), where domain shifts occur due to synthetic data, lighting, weather, or location changes. Vision-language models (VLMs) marked a large step for the generalization capabilities and have been already applied to various tasks. Very recently, first approaches utilized VLMs for domain generalized segmentation and object detection and obtained strong generalization. However, all these approaches rely on complex modules, feature augmentation frameworks or additional models.
Surprisingly and in contrast to that, we found that simple fine-tuning of vision-language pre-trained models yields competitive or even stronger generalization results while being extremely simple to apply. Moreover, we found that vision-language pre-training consistently provides better generalization than the previous standard of vision-only pre-training. This challenges the standard of using ImageNet-based transfer learning for domain generalization.
Fully fine-tuning a vision-language pre-trained model is capable of reaching the domain generalization SOTA when training on the synthetic GTA5 dataset. Moreover, we confirm this observation for object detection on a novel synthetic-to-real benchmark. We further obtain superior generalization capabilities by reaching 77.9% mIoU on the popular Cityscapes→ACDC benchmark. We also found improved in-domain generalization, leading to an improved SOTA of 86.4% mIoU on the Cityscapes test set, marking the first place on the leaderboard.

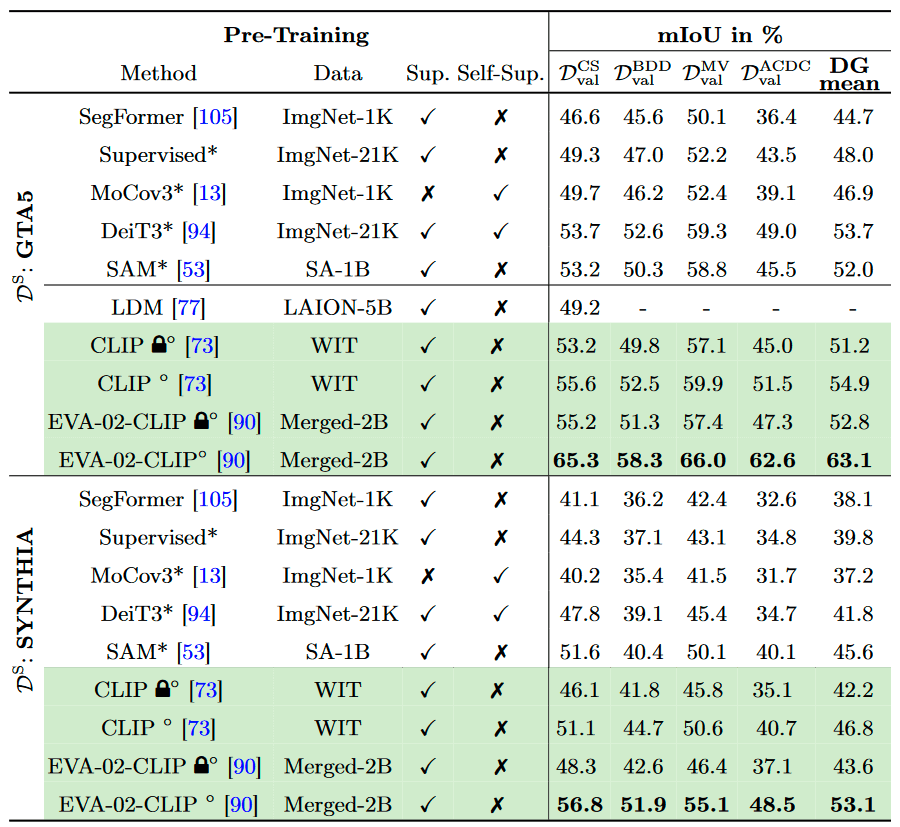
Transfer Learning: Domain Generalization Performance of supervised training on GTA5 and SYNTHIA. * denotes that the ViT-L-16 was used as the encoder. ◦ denotes that ViT-L-14 was used as the encoder. 🔒 denotes frozen encoder weights.
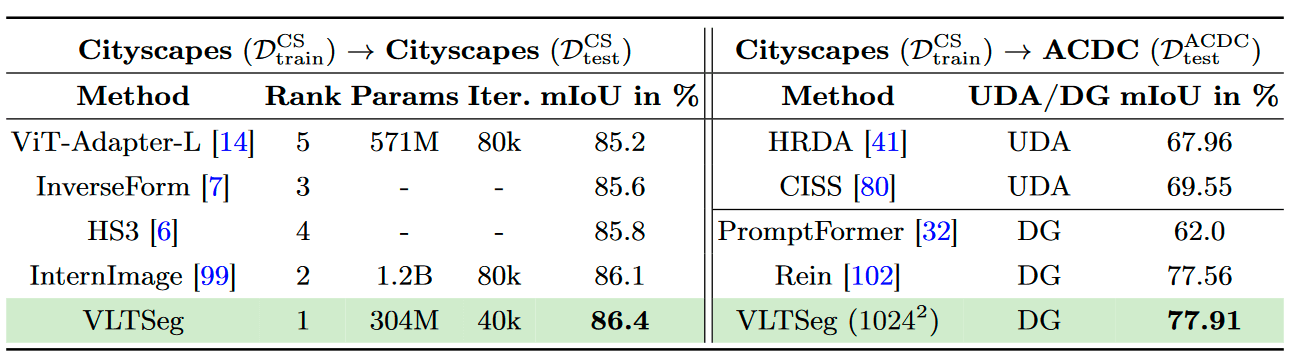
State-of-the-Art performance of VLTSeg on Cityscapes and ACDC Test Set.
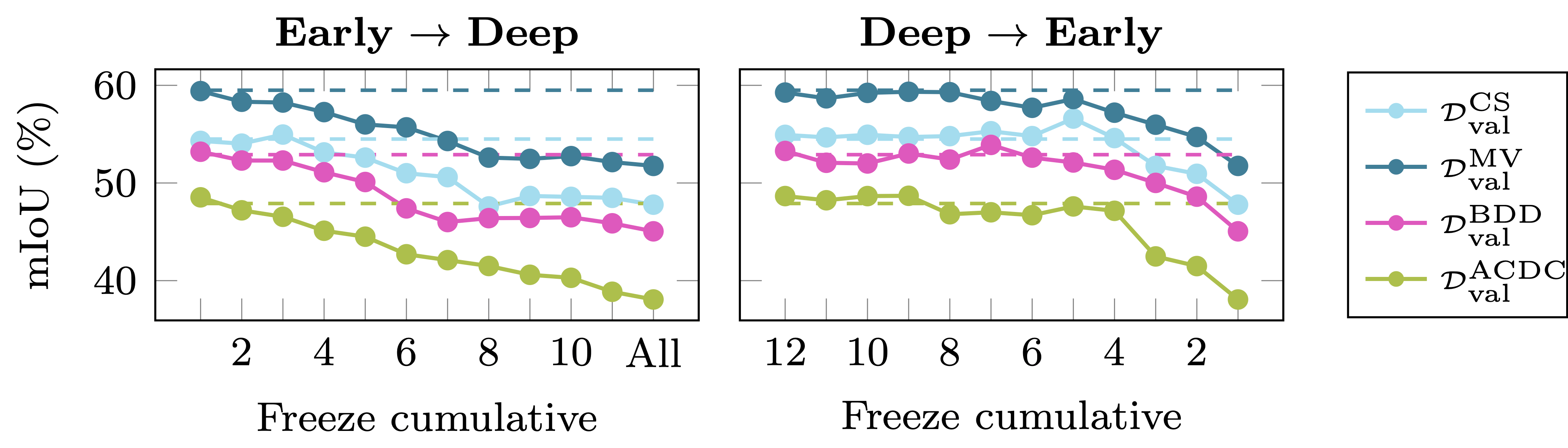
Ablation of freezing encoder layers for the syn-to-real DG performance. Training on GTA5 with EVA-02-ViT-B-16. Dashed lines indicate full fine-tuning.
@inproceedings{huemmer2024accv,
author={Hümmer, Christoph and Schwonberg, Manuel and Zhou, Liangwei and Cao, Hu and Knoll, Alois and Gottschalk, Hanno},
booktitle={ACCV},
title={Strong but Simple: A Baseline for Domain Generalized Dense Perception by CLIP-based Transfer Learning},
year={2024}
}